
国外speaking实践过程拍击:惊现笑料不断,传播跨文化交流真谛
60114 2023-12-23 08:50

在这个信息爆炸的时代,数据已经成为了我们生活中不可或缺的一部分。而Hive数据仓库,正是这个数据海洋中的一艘巨轮,带领我们在数据的海洋中扬帆启航,探索未知的奥秘。
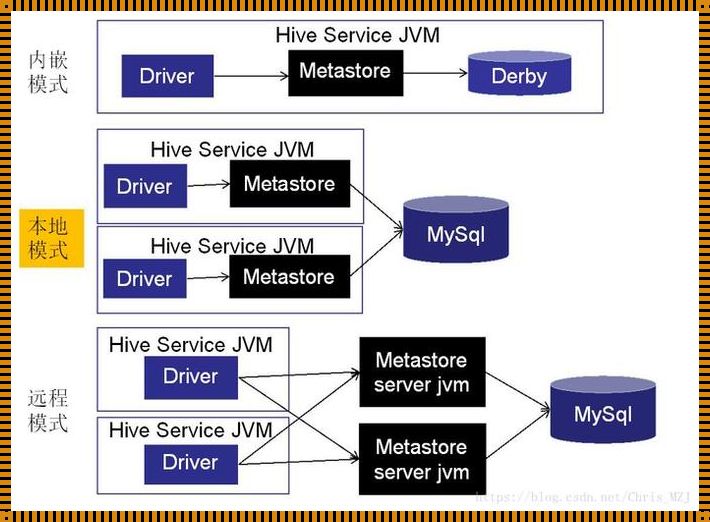
Hive,作为一种基于Hadoop的分布式数据仓库系统,它的出现让我们对数据的管理和分析变得更加简单和高效。它允许我们将结构化数据存储在Hadoop分布式文件系统(HDFS)中,并通过Hive查询语言(HiveQL)来进行数据查询和分析。这种设计使得Hive既具备了传统数据仓库的稳定性和可靠性,又具备了大数据处理的灵活性和可扩展性。
Hive的架构设计也非常独特,它由元数据存储库、编译器、执行引擎和用户界面等多个组件组成。这些组件相互配合,共同完成了数据的存储、查询和分析工作。其中,元数据存储库负责存储有关Hive表和分区的信息;编译器将HiveQL查询转换为MapReduce作业;执行引擎负责执行MapReduce作业并生成查询结果;用户界面则提供了交互式查询和数据可视化工具,使得用户可以更方便地操作和使用Hive。
Hive的特点也非常明显,它易于使用,因为HiveQL类似于SQL,熟悉SQL的用户可以轻松上手。同时,Hive的性能非常高,它可以处理海量数据,并通过MapReduce并行处理来提高查询速度。此外,Hive还具有很好的可扩展性,可以轻松扩展到数百或数千台服务器,以满足不断增长的数据需求。最后,Hive与Hadoop生态系统紧密集成,可以与其他Hadoop组件无缝协作,具有很好的兼容性。
在实际应用中,Hive数据仓库可以广泛应用于数据仓库、数据挖掘和机器学习等领域。例如,企业可以利用Hive构建大规模、高性能的数据仓库,进行数据分析和商业智能;数据科学家可以利用Hive挖掘隐藏在数据中的信息,帮助企业做出更好的决策;机器学习工程师可以利用Hive为机器学习算法提供大量训练数据,帮助算法提高准确性。
总的来说,Hive数据仓库为我们提供了一个强大的工具,让我们在数据的海洋中自由航行,探索数据的奥秘。无论是数据分析师、商业智能专家还是机器学习工程师,都可以借助Hive来实现自己的目标。所以,让我们一起开启Hive之旅,解锁数据背后的无限可能吧!





