
国外speaking实践过程拍击:惊现笑料不断,传播跨文化交流真谛
61455 2023-12-23 08:50

在统计学中,哑变量,也被称作虚拟变量或指示变量,通常用于表示分类数据。当面对多组分类数据时,如何将这些哑变量有效地纳入回归模型中,是一个需要谨慎处理的问题。
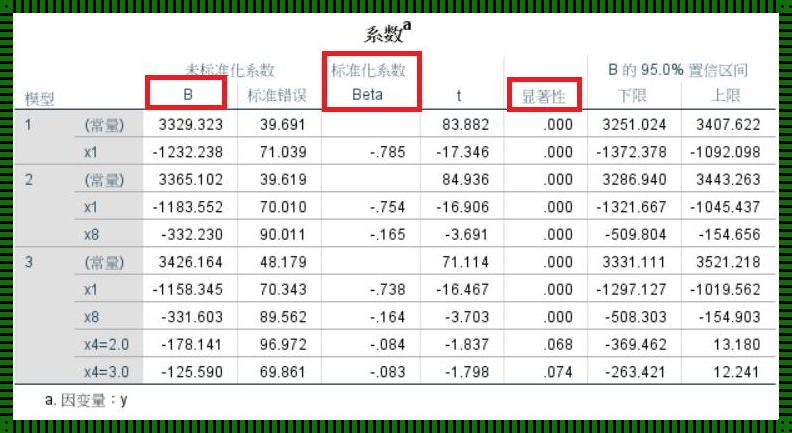
哑变量通过分配1和0来代表某个类别中的个体属于某一类别还是不属于该类别。例如,性别可以是一个二元分类的哑变量,其中男性为1,女性为0。在回归分析中,哑变量的目的是将分类数据转换为可以进行分析的数值型数据。
纳入回归模型时,一个常见的错误是直接将多个哑变量直接纳入模型,这可能会导致所谓的“多重共线性”问题。多重共线性是指模型中两个或多个解释变量彼此之间存在较高的相关性。当出现多重共线性时,回归系数估计的准确性会受到影响,可能导致模型预测的不稳定。
为了解决这个问题,我们可以采用一种称为“独热编码”(one-hot encoding)的技术。独热编码将每个类别转换为一个独热向量,即一个包含1和0的向量,其中只有一个元素为1,其余为0。这样,每个个体都会根据其类别有一个独特的向量表示。然而,这种方法在回归模型中会导致大量的虚拟变量,尤其是当类别很多时,这会增加模型的复杂度并影响计算的可行性。
一个更有效的方法是使用“有序哑变量”(ordered dummy variables)。有序哑变量仅对类别间的顺序进行编码,而不是对每个单独的类别进行编码。这种方法要求类别之间是有序的,并且它允许模型捕捉到类别之间的顺序关系。
另一种策略是使用“随机效应模型”(random effects models),特别是当类别数据是层次结构的时候。这种模型允许类别数据中的随机效应,可以更准确地捕捉到数据中的结构。
在实践中,选择哪种方法取决于数据的性质、模型的目的以及计算的资源。通常,需要通过模型诊断和交叉验证来确定最佳的方法。
总之,将多组哑变量纳入回归模型需要仔细考虑数据的结构和模型的目的。通过合理地处理哑变量,我们可以构建出更准确、更稳健的回归模型,从而为决策提供有力的支持。





