
国外speaking实践过程拍击:惊现笑料不断,传播跨文化交流真谛
61282 2023-12-23 08:50

(1)绝对值编码器1212是一种数字编码器,用于将机械位置转换为数字信号。它可以精确地测量旋转或线性运动的位置,并将其转换为数字信号,以便计算机或控制器可以读取和处理。
(2)重载型绝对值编码器是一种用于将模拟信号转换为数字信号的编码器。它的主要作用是将输入信号的绝对值转换为二进制码,并输出给数字系统进行处理。在数字系统中,信号通常以二进制码的形式进行处理和传输。
(3)绝对式编码器是利用自然二进制或循环二进制(葛莱码)方式进行光电转换的。绝对式编码器与增量式编码器不同之处在于圆盘上透光、不透光的线条图形,绝对编码器可有若干编码,根据读出码盘上的编码,检测绝对位置。
(4)增量编码器是一圈(列)的磁极对,绝对是2圈(2列或3列)的磁极对,通过游标卡尺的Nonius原理实现单圈位置的绝对测量。倍加福绝对值编码器是一种用于测量旋转物体角度的设备,它将旋转角度转换成相应的电信号输出。
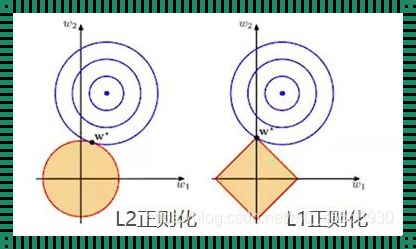
1、L1正则是拉普拉斯先验,L2是高斯先验。整个最优化问题可以看做是一个最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计。
2、这样的方法被称作L1正则化,也就是Lasso回归的方式。因为Lasso趋向于使得一部分\theta为所以Lasso可以做 特征选择 。此外还有一种L0正则,也就是引入一项,使得的个数尽可能的小。
3、L1正则化就是在 loss function 后面加上L1范数,这样比较容易求到稀疏解。
4、在支持向量机(support vector machine)学习过程中,实际是一种对于成本函数(cost function)求解最优的过程。 例如我们有一个数学模型的样子(structure), ,其中x是输入,y是输出。
L1正则化就是在 loss function 后面加上L1范数,这样比较容易求到稀疏解。

L1正则是拉普拉斯先验,L2是高斯先验。整个最优化问题可以看做是一个最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计。
这样的正则化就是L2正则化,就是加了一个平方项。如果不加平方项,而是绝对值:这样的方法被称作L1正则化,也就是Lasso回归的方式。因为Lasso趋向于使得一部分\theta为所以Lasso可以做 特征选择 。
L2范数: 除了L1范数,还有一种更受宠幸的规则化范数是L2范数: ||W||在回归里面,有人把它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。
正则化(Regularization) 机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作 ℓ1-norm 和 ℓ2-norm ,中文称作 L1正则化 和 L2正则化 ,或者 L1范数 和 L2范数 。
《1》L1正则是拉普拉斯先验,L2是高斯先验。整个最优化问题可以看做是一个最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计。
《2》正则化和变分法,构建一个描述解特性的连续全局能量函数,然后用稀疏线性系统或相关迭代方法找到最小能量解,贝叶斯统计学对产生输入图像的有噪声的测量过程和关于解空间的先验假设进行建模,通常用马尔科夫随机场进行编码。
《3》正则化表示为 ,如果i=j为 属于边为 ,否则为拉普拉斯算子是n维欧式空间中的一个二阶算子,如果将算子退化到离散二维图像空间,变成了边缘检测算子。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
L1正则化项也称为Lasso,L2正则化参数也称为Ridge。 L1范数:权值向量w中各个元素的绝对值之和,L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数。求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的。
这样的正则化就是L2正则化,就是加了一个平方项。如果不加平方项,而是绝对值:这样的方法被称作L1正则化,也就是Lasso回归的方式。因为Lasso趋向于使得一部分\theta为所以Lasso可以做 特征选择 。
L1正则化就是在 loss function 后面加上L1范数,这样比较容易求到稀疏解。
特征提升 清理数据。 这一步要做的是在数据理解的基础上,得到一个比较整齐的数据。把未结构化的数据结构化、填充空值、对数据标准化。其中标准化包括z-socre标准化,min-max标准化,还有L1和L2正则化。
L1正则化表示各个参数绝对值之和。 L2正则化标识各个参数的平方的和的开方值。 L0正则化 保证参数稀疏化来防止过拟合,可以用非零参数,来进行特征选择。但是L0正则化不好求,因此采用L1正则化。





