
国外speaking实践过程拍击:惊现笑料不断,传播跨文化交流真谛
61353 2023-12-23 08:50

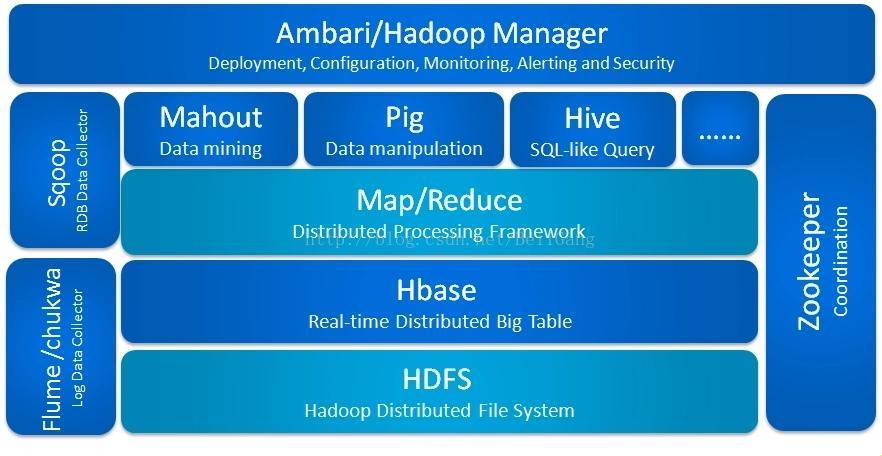
在众多大数据技术中,Hadoop家族独树一帜,吸引了无数眼球。它的五大组件:HDFS、MapReduce、YARN、HBase和Hive,共同演绎了一场数据处理的华丽舞剧。然而,在这璀璨的舞台背后,总有那么几个“倒霉蛋”被人们遗忘。今天,就让我们揭开这神秘的面纱,探寻一下不是Hadoop组件的“失落宝藏”。
“你确定要讲这个话题?”旁边的某位仁兄一脸坏笑地问我,“人家Hadoop都风光无限了,你还去关注那些边缘角色,这不是自己找虐吗?”
“嘿,这你就不懂了吧。”我白了他一眼,“正所谓‘物以稀为贵’,这些被人遗忘的技术,也许藏着意想不到的宝藏呢。”
首先,让我们把目光投向这位“背锅侠”——ZooKeeper。在Hadoop生态系统中,ZooKeeper承担着分布式协调服务的重任,但它并非Hadoop的核心组件。虽然名字里有个“Zoo”,但它可不是用来管理动物的。我忍不住想为它鸣不平:“人家ZooKeeper兢兢业业,保障了Hadoop集群的稳定运行,怎么就成‘背锅侠’了呢?”
接着,我们来看看这位“低调先生”——Pig。作为Hadoop生态圈的一员,Pig致力于简化复杂的数据转换过程,但它却常常被人们忽视。也许你会问:“Pig?那不是猪吗?”没错,它的名字确实来源于猪,但这并不妨碍它在大数据领域发光发热。我想说:“别看人家名字土,实用性还是很强的!”
再来认识一下这位“边缘人”——Sqoop。作为数据迁移工具,Sqoop负责将数据在关系数据库和Hadoop之间传输,然而它的地位却略显尴尬。有人调侃道:“Sqoop?那不是河马吗?”嘿,你还真别说,人家河马可是个“搬运工”,辛勤地将数据搬来搬去,为Hadoop生态圈的发展做出了贡献。
最后,让我们关注一下这位“潜力股”——Flume。作为日志收集工具,Flume在Hadoop生态系统中发挥着重要作用。然而,它的知名度似乎并不高。我忍不住想为它呐喊:“Flume,你就像那默默无闻的‘扫地僧’,总有一天会让大家刮目相看的!”
“唉,归纳起来说,你觉得这些技术真的有用吗?”旁边的某位仁兄又发话了。
我瞪了他一眼:“当然有用!这些技术虽然在Hadoop家族中显得不那么起眼,但它们各有所长,为大数据处理提供了多样化的解决方案。正所谓‘尺有所短,寸有所长’,我们不能因为它们不是Hadoop的核心组件就忽视它们的价值。”
“那你干嘛不选它们?”他挑衅地问道。
“我……”我一时语塞,然后无奈地笑了笑,“也许是因为它们不够‘主流’吧。但在某些特定场景下,它们确实是解决问题的最佳选择。所以,别小看这些‘边缘角色’,它们可是潜在的宝藏哦!”





