
国外speaking实践过程拍击:惊现笑料不断,传播跨文化交流真谛
60082 2023-12-23 08:50

在当今这个信息爆炸的时代,大数据处理技术显得尤为重要。Spark作为大数据处理领域的佼佼者,其工作原理一直是研究和学习大数据技术的焦点。本文将深入剖析Spark的工作原理,帮助你理解这个神奇的大数据处理引擎。
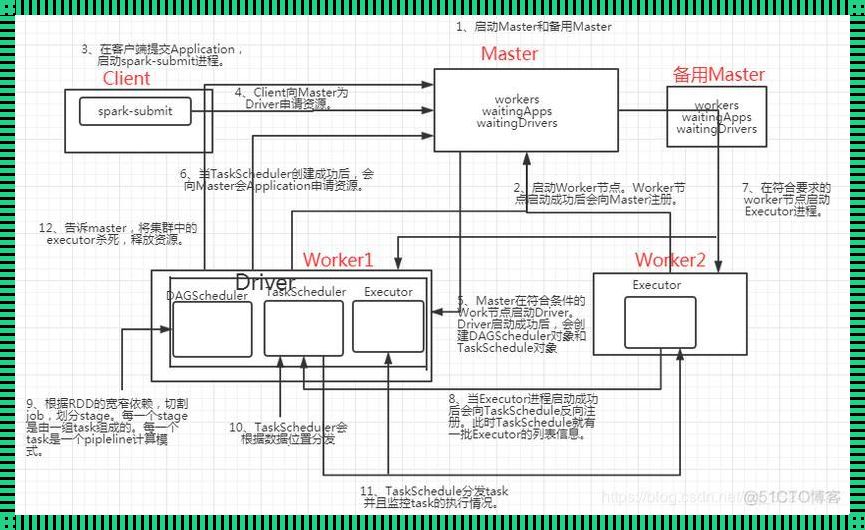
Spark是一个开源的大数据处理框架,它提供了分布式数据处理的快速、通用、可扩展的能力,被广泛应用于大数据领域。Spark的核心组件包括Spark Core、Spark SQL、Spark Streaming、MLlib机器学习库等。
Spark工作原理可以概括为:将大规模数据集分成许多小任务,分散到集群中的各个节点上进行处理,最后将结果汇总。这个过程包括了数据处理、任务调度、内存管理等多个环节。
数据处理:Spark采用分布式数据集(Resilient Distributed Dataset, RDD)作为数据处理的基石。RDD是一个不可变的、分布式的数据集合,可以进行各种数据操作,如map、reduce、filter等。RDD的特点是数据备份和错误恢复能力强,可以保证数据处理过程中不丢失数据。
任务调度:Spark采用了一种称为DAGScheduler的任务调度器,实现了任务的并行执行。DAGScheduler将用户编写的程序解析成一个有向无环图(Directed Acyclic Graph, DAG),然后根据集群资源情况,将DAG划分为多个小任务,并行执行。任务调度过程中,Spark会尽量平衡各个任务之间的资源消耗,确保集群资源得到充分利用。
内存管理:Spark采用了可扩展的内存管理策略,包括堆外内存管理、自动内存管理等。堆外内存管理允许Spark直接操作操作系统内存,提高了内存使用效率。自动内存管理则通过监控集群内存使用情况,动态调整内存分配策略,确保集群资源得到充分利用。
总之,Spark的工作原理涵盖了数据处理、任务调度、内存管理等多个方面,形成了一个高效、可靠的大数据处理引擎。理解Spark的工作原理,有助于我们更好地利用Spark处理大数据,挖掘数据价值,为我国大数据产业的发展贡献力量。





