
国外speaking实践过程拍击:惊现笑料不断,传播跨文化交流真谛
61564 2023-12-23 08:50

K-Means算法,一个在数据挖掘和机器学习领域耳熟能详的名字。当我们谈论到数据聚类时,这个名字总是会被提及。今天,让我们揭开这层神秘的面纱,一探究竟。
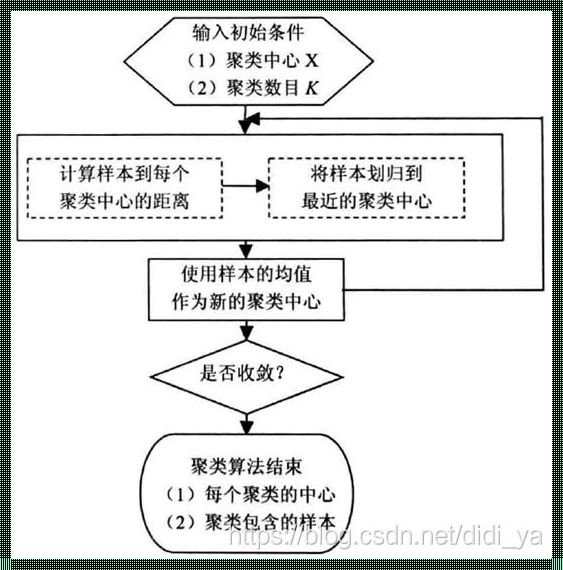
K-Means算法的基本思想是将数据分为K个簇(Cluster),每个簇内的数据点尽可能相似,而不同簇的数据点尽可能不同。如何衡量相似度呢?常用的方法是计算数据点之间的距离。在K-Means算法中,我们通常使用欧氏距离来计算。
算法流程如下:
K-Means算法简单、高效,但并非完美。它有以下几个缺点:
尽管如此,K-Means算法在许多领域仍然有着广泛的应用。原因在于:
在实际应用中,我们可以通过调整算法参数和选择合适的距离度量来优化聚类效果。此外,还可以采用一些改进的K-Means算法,如K-Means++,以提高算法的稳定性和聚类质量。
总之,K-Means算法是一个实用的数据聚类方法。虽然它有不足之处,但通过合理的方法和技巧,我们可以在实际应用中取得满意的聚类效果。正如一句古语所说:“尺有所短,寸有所长”,K-Means算法亦如此。





